OLaLa: OM with LLMs¶
OLaLa¶
OLaLa (Ontology matching with Large Language models) is a retrieval-augmented ontology alignment system that combines dense semantic retrieval with open-source decoder language models to verify candidate correspondences. Key properties of OLaLa are:
Zero-shot / few-shot — Requires no labelled training pairs; a small set of in-context examples is sufficient.
Open-source LLMs only — All results are reproducible; no paid API is involved.
Confidence-calibrated — Binary yes/no token probabilities are normalised into a
[0, 1]confidence score.High-precision safety net — An exact-match high-precision matcher supplements the LLM to recover trivial correspondences at full confidence.
Postprocessing pipeline — Bad-host filtering, maximum-weight bipartite extraction, and confidence thresholding produce a clean one-to-one alignment.
The following diagram (Figure 1 of the paper) illustrates the overall OLaLa pipeline:
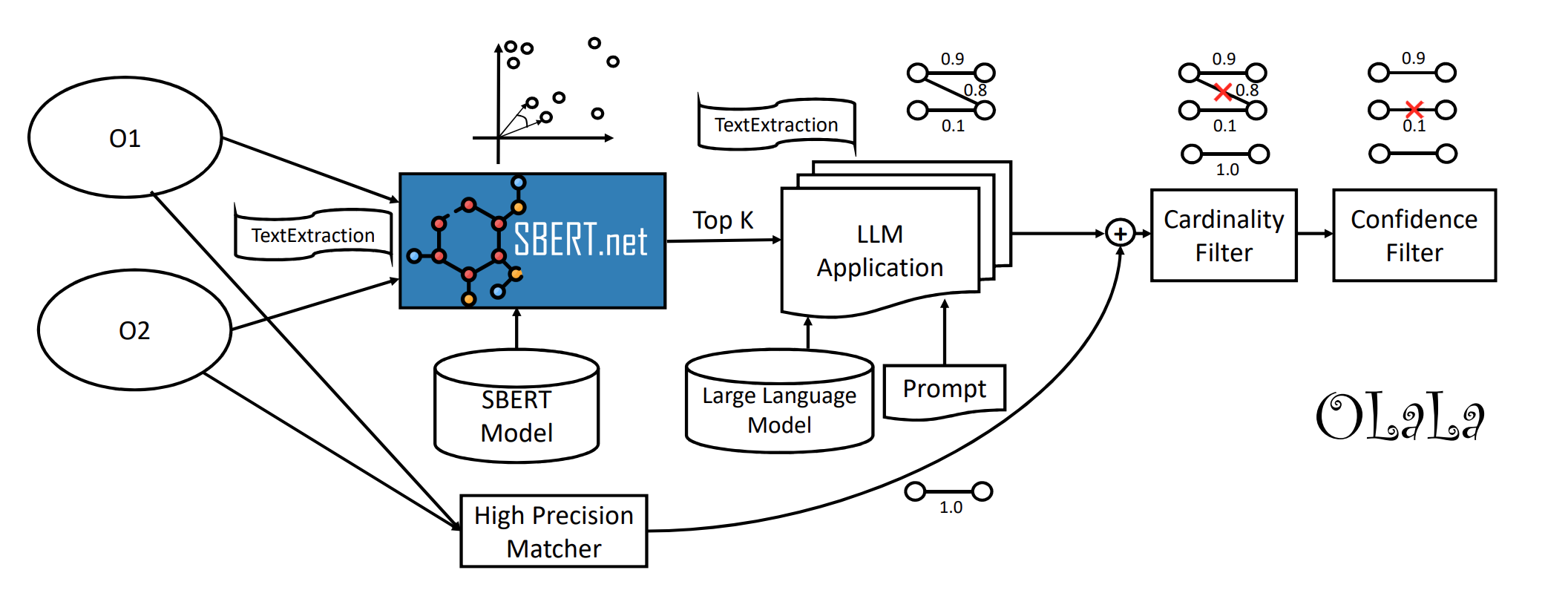
Given two ontologies \(O_1\) and \(O_2\), OLaLa produces a set of correspondence pairs \(M = \{(c, c', s) \mid c \in O_1,\; c' \in O_2,\; s \in [0,1]\}\), where \(s\) is the LLM-derived confidence that concepts \(c\) and \(c'\) refer to the same real-world entity. The pipeline has four stages:
🔍 1. Candidate Generation (SBERT): Each ontology concept is verbalized into one or more text strings using the TextExtractorSet strategy — extracting labels, descriptions, annotation-property texts, and the URI fragment (when it contains fewer than 50 % digits). All texts per resource are embedded with a Sentence-BERT model and a bidirectional cosine-similarity search returns the top-k candidates per resource. The default model is multi-qa-mpnet-base-dot-v1, and k = 5. The procedure is run in both directions (source → target and target → source), and the union of candidates is kept.
🤖 2. LLM Binary Verification: Each candidate pair is presented to a decoder LLM via a few-shot prompt (prompt 7 in the paper — see the Prompts section below):
Classify if two descriptions refer to the same real world entity (ontology matching).
### Concept one: endocrine pancreas secretion ### Concept two: Pancreatic Endocrine Secretion ### Answer: yes
### Concept one: urinary bladder urothelium ### Concept two: Transitional Epithelium ### Answer: no
### Concept one: trigeminal V nerve ophthalmic division ### Concept two: Ophthalmic Nerve ### Answer: yes
### Concept one: foot digit 1 phalanx ### Concept two: Foot Digit 2 Phalanx ### Answer: no
### Concept one: large intestine ### Concept two: Colon ### Answer: no
### Concept one: ocular refractive media ### Concept two: Refractile Media ### Answer: yes
### Concept one: {left} ### Concept two: {right} ### Answer:
Generation stops as soon as a yes / no (or true / false) token is produced. The softmax probability of the positive class is normalised by the sum of positive and negative class probabilities to yield a confidence score: \(s = p_{yes}/(p_{yes} + p_{no})\), where every correspondence with \(s \geq 0.5\) is treated as a positive match.
🎯 3. High-Precision Matching: In parallel, an exact-match high-precision matcher independently finds concepts with identical normalized labels or URI fragments (lowercased, camel-case split, non-alphanumeric characters removed). Only unambiguous 1:1 pairs (no N:M conflicts) are kept, all at confidence 1.0. These are merged into the LLM output to ensure trivial correspondences are never missed.
🧹 4. Postprocessing: The merged alignment is cleaned in three steps:
Bad-host filter — removes correspondences whose IRIs do not belong to the expected source or target ontology hosts.
Maximum-weight bipartite extraction — enforces a one-to-one mapping by solving the assignment problem with
scipy.optimize.linear_sum_assignment.Confidence filter — discards all correspondences below a configurable threshold (default 0.5).
Note
Reference: Sven Hertling and Heiko Paulheim. 2023. OLaLa: Ontology Matching with Large Language Models. In Proceedings of the 12th Knowledge Capture Conference 2023 (K-CAP ‘23). Association for Computing Machinery, New York, NY, USA, 131–139. https://doi.org/10.1145/3587259.3627571
Usage¶
Import the OLaLa pipeline components and utility modules.
import json
from ontoaligner.ontology import OLaLaOMDataset
from ontoaligner.encoder import OLaLaEncoder
from ontoaligner.aligner.olala import (
OLaLaSBERTRetrieval,
OLaLaLLMAligner,
OLaLaHighPrecisionMatcher,
OLaLaAligner,
)
from ontoaligner.aligner.olala.postprocessor import olala_postprocessor
from ontoaligner.utils import metrics, xmlify
Note
OLaLaAligner is a thin orchestrator that wires together the retriever,
the LLM aligner, and the high-precision matcher.
Each component can also be used independently.
OLaLaOMDataset.collect() calls OLaLaOntology.parse() for each OWL file.
The parser extracts standard fields and OLaLa-specific fields (TextExtractorSet,
OnlyLabel, high-precision texts, host) into an "olala" sub-dictionary
on every concept.
task = OLaLaOMDataset(language="en")
print("Task:", task)
dataset = task.collect(
source_ontology_path="assets/source.owl",
target_ontology_path="assets/target.owl",
reference_matching_path="assets/reference.xml", # optional, for evaluation
)
Each entry in dataset["source"] / dataset["target"] has the shape:
{
"iri": "http://purl.obolibrary.org/obo/MA_0000001",
"label": "mouse",
"olala": {
"text_extractor_set": ["mouse", ...],
"normalized_text_extractor_set": ["mouse", ...],
"only_label": "mouse",
"hp_texts": ["mouse"],
"host": "purl.obolibrary.org",
"normalized_label": "mouse",
"normalized_uri_fragment": "ma 0000001",
...
}
}
Warning
Only OWL/XML ontologies are supported out of the box. For other RDF serializations, supply a custom parser.
OLaLaEncoder converts the parsed ontology items into the flat lists expected
by the retriever, LLM aligner, and high-precision matcher.
encoder_model = OLaLaEncoder()
encoded_ontology = encoder_model(
source=dataset["source"],
target=dataset["target"],
)
# encoded_ontology == [source_items, target_items]
Each item in source_items / target_items exposes the fields
texts, only_label, hp_texts, keep_for_sbert, and expected_host
used by the downstream components.
Instantiate the three OLaLa components — retriever, LLM aligner, and
high-precision matcher — then wire them into OLaLaAligner.
# SBERT candidate retriever
retriever = OLaLaSBERTRetrieval(
device="cuda",
top_k=5,
both_directions=True,
topk_per_resource=True,
)
# LLM binary verifier
llm_aligner = OLaLaLLMAligner(
device="cuda",
max_new_tokens=10,
temperature=0.0,
truncation=True,
max_length=2048,
padding=True,
loading_arguments={
"device_map": "auto",
"torch_dtype": "torch.float16",
},
)
# High-precision exact matcher
hp_aligner = OLaLaHighPrecisionMatcher(confidence=1.0)
# Orchestrator
olala = OLaLaAligner(
retriever=retriever,
llm_aligner=llm_aligner,
hp_aligner=hp_aligner,
)
See Configuration below for a complete parameter reference.
Load the SBERT and LLM weights, then call generate().
olala.load(
llm_path="upstage/Llama-2-70b-instruct-v2",
retriever_path="multi-qa-mpnet-base-dot-v1",
)
alignments = olala.generate(input_data=encoded_ontology)
The raw output is a flat list of grouped LLM predictions and high-precision
correspondences, each tagged with an alignment_type field:
[
{
"alignment_type": "rag",
"source": "http://example.org/A",
"target-cands": ["http://example.org/B", ...],
"score-cands": [0.87, ...]
},
{
"alignment_type": "hp",
"source": "http://example.org/C",
"target": "http://example.org/D",
"score": 1.0
},
...
]
olala_postprocessor merges LLM and high-precision predictions, applies
host filtering, extracts a one-to-one alignment, and applies the confidence threshold.
final_matchings = olala_postprocessor(
alignments,
encoded_ontology,
confidence_threshold=0.5,
strict_bad_hosts=False,
)
The output is a clean list of flat correspondences:
[
{"source": "http://example.org/A", "target": "http://example.org/B", "score": 0.87},
...
]
Compare predictions to a reference alignment and export results.
# Evaluate
evaluation = metrics.evaluation_report(
predicts=final_matchings,
references=dataset["reference"],
)
print("OLaLa Evaluation Report:")
print(json.dumps(evaluation, indent=4))
Example output:
{
"intersection": 1317,
"precision": 89.4,
"recall": 89.1,
"f-score": 90.2,
"predictions-len": 1478,
"reference-len": 1478
}
Export the final alignment to XML (OAEI-compatible) or JSON:
xml_str = xmlify.xml_alignment_generator(matchings=final_matchings)
with open("olala_matchings.xml", "w", encoding="utf-8") as f:
f.write(xml_str)
with open("olala_matchings.json", "w", encoding="utf-8") as f:
json.dump(final_matchings, f, indent=4, ensure_ascii=False)
Configuration¶
Parameter |
Type |
Default |
Description |
|---|---|---|---|
device |
str |
|
Device for the SentenceTransformers model ( |
top_k |
int |
|
Number of candidate targets retrieved per source resource. Higher values increase recall but increase LLM inference cost. |
both_directions |
bool |
|
If |
topk_per_resource |
bool |
|
If |
Parameter |
Type |
Default |
Description |
|---|---|---|---|
device |
str |
|
Device for the language model ( |
max_new_tokens |
int |
|
Maximum number of tokens the model is allowed to generate per prompt. Generation usually stops early when a yes/no token is detected. |
temperature |
float |
|
Sampling temperature. Set to |
word_stopper |
bool |
|
If |
loading_arguments |
dict |
|
Extra keyword arguments forwarded to |
system_prompt_template |
str |
|
Optional wrapper around the filled prompt.
Use this to add a system message for chat-tuned models,
e.g. |
dataset_class |
type |
|
Dataset class used to build prompts. Override to customise text verbalization. |
truncation |
bool |
|
Whether to truncate inputs that exceed |
max_length |
int |
|
Maximum tokenized input length. |
padding |
bool |
|
Whether to pad inputs to the same length within a batch. |
Parameter |
Type |
Default |
Description |
|---|---|---|---|
confidence |
float |
|
Confidence score assigned to every exact correspondence produced by
this matcher. Should remain at |
Parameter |
Type |
Default |
Description |
|---|---|---|---|
alignments |
list |
— |
Raw output of |
encoded_ontology |
list |
— |
|
confidence_threshold |
float |
|
Correspondences with scores below this value are discarded.
The default removes all pairs where the LLM preferred |
strict_bad_hosts |
bool |
|
If |
Complete Configuration Example
retriever = OLaLaSBERTRetrieval(
device="cuda",
top_k=5,
both_directions=True,
topk_per_resource=True,
)
llm_aligner = OLaLaLLMAligner(
device="cuda",
max_new_tokens=10,
temperature=0.0,
truncation=True,
max_length=2048,
padding=True,
system_prompt_template="[INST] {user_prompt} [/INST]",
loading_arguments={
"device_map": "auto",
"torch_dtype": "torch.float16",
"load_in_8bit": True,
},
)
hp_aligner = OLaLaHighPrecisionMatcher(confidence=1.0)
olala = OLaLaAligner(
retriever=retriever,
llm_aligner=llm_aligner,
hp_aligner=hp_aligner,
)
Prompts¶
OLaLa supports both zero-shot and few-shot prompting strategies. The table below summarises the prompts evaluated in the paper’s ablation study on the anatomy track. Prompt 7 (the default few-shot prompt) achieves the best balance between F-measure and runtime.
ID |
Prompt template |
Prec |
Rec |
F1 |
Time |
|---|---|---|---|---|---|
0 (zero-shot) |
|
0.853 |
0.866 |
0.861 |
4h 19m |
7 (default) |
Few-shot with 3 positive + 3 negative examples and task description (see below) |
0.914 |
0.891 |
0.902 |
2h 41m |
The default prompt 7 used by OLaLaLLMDataset is:
Classify if two descriptions refer to the same real world entity (ontology matching).
### Concept one: endocrine pancreas secretion ### Concept two: Pancreatic Endocrine Secretion ### Answer: yes
### Concept one: urinary bladder urothelium ### Concept two: Transitional Epithelium ### Answer: no
### Concept one: trigeminal V nerve ophthalmic division ### Concept two: Ophthalmic Nerve ### Answer: yes
### Concept one: foot digit 1 phalanx ### Concept two: Foot Digit 2 Phalanx ### Answer: no
### Concept one: large intestine ### Concept two: Colon ### Answer: no
### Concept one: ocular refractive media ### Concept two: Refractile Media ### Answer: yes
### Concept one: {left} ### Concept two: {right} ### Answer:
Note
To use a custom prompt, subclass OLaLaLLMDataset, override the prompt class attribute,
and pass your subclass via the dataset_class argument of OLaLaLLMAligner.
Advanced Usage¶
🔧 Custom System Prompt (Chat Models) Usage: Chat-tuned models such as Llama-2-70b-chat-hf expect a specific conversation template. Pass system_prompt_template to wrap the filled few-shot prompt:
llm_aligner = OLaLaLLMAligner(
system_prompt_template="[INST] {user_prompt} [/INST]",
...
)
⚡ Lightweight / CPU Mode Usage: For quick experiments without GPU access, reduce the model size and disable 8-bit loading:
retriever = OLaLaSBERTRetrieval(device="cpu", top_k=3)
llm_aligner = OLaLaLLMAligner(
device="cpu",
loading_arguments={"torch_dtype": "torch.float32"},
)
Consider using a smaller model such as ``meta-llama/Llama-2-7b-hf`.
🔬 Components Standalone Usage: Each component can be used independently of OLaLaAligner:
# SBERT retrieval only
retriever = OLaLaSBERTRetrieval(device="cuda", top_k=5)
retriever.load(path="multi-qa-mpnet-base-dot-v1")
candidates = retriever.generate(input_data=encoded_ontology)
# LLM aligner only (accepts SBERT candidates)
llm_aligner = OLaLaLLMAligner(device="cuda", ...)
llm_aligner.load(path="upstage/Llama-2-70b-instruct-v2")
llm_predictions = llm_aligner.generate(
input_data=[source_items, target_items, candidates]
)
# High-precision matcher only
hp_aligner = OLaLaHighPrecisionMatcher(confidence=1.0)
hp_predictions = hp_aligner.generate(input_data=encoded_ontology)
When to use the standalone matcher
Scenario |
Recommendation |
|---|---|
Fast baseline / sanity check |
Run standalone; takes seconds even on large ontologies. |
Ontologies with highly consistent labelling conventions |
Standalone HighPrecisionMatcher may already achieve acceptable recall. |
Pre-filtering before a costly LLM run |
Run HP first, remove matched concepts, then feed the remainder to |
Full production alignment |
Use |
Hint
See also the Package Reference > OLaLa Aligner.