Ensemble Learning Aligner¶
Ensemble Learning¶
Ensemble Learning combines predictions from multiple ontology alignment pipelines to produce a final set of correspondences. In OntoAligner, ensemble learning is handled by EnsembleLearningAligner, where each ensemble member is represented as a branch configured with AlignerPipeline.
Each branch follows the standard OntoAligner flow: encode the ontology matching dataset, load the aligner when needed, generate predictions, and optionally apply branch-level postprocessing. Postprocessing may be required before voting for LLM, RAG, and KGE outputs because these aligners may produce outputs that need conversion or filtering before fusion.
Hint
Why Ensemble Learning for Ontology Alignment?
Complementary Signals: Combines lexical similarity, semantic retrieval, graph structure, and LLM/RAG-based verification from different aligners.
Robustness: Reduces reliance on a single aligner, which can help balance the weaknesses of individual models.
Model-Agnostic Fusion: Allows heterogeneous aligner families to contribute through a shared voting strategy and produce one final alignment.
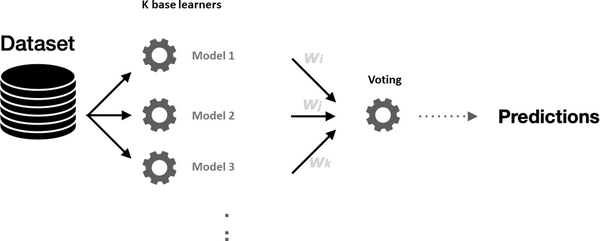
The ensemble workflow has four stages:
🔧 1. Branch Configuration: Multiple AlignerPipeline are configured with encoders, aligners, datasets, optional loading parameters, and optional postprocessors.
⚙️ 2. Branch Prediction: Each branch generates correspondences independently using lightweight, retrieval, KGE, LLM, or RAG-based aligners.
🧩 3. Output Normalization: Branch outputs are converted into a common source-target-score format before fusion.
🗳️ 4. Voting: A voting method combines weighted branch outputs into the final matchings.
Usage¶
This module guides you through a step-by-step process for performing ensemble-based ontology alignment using multiple OntoAligner models. By the end, you’ll understand how to configure aligner pipeline, combine their predictions with voting strategies, evaluate the final matchings, and save the outputs in XML and JSON formats.
Import the dataset classes, encoders, aligners, postprocessors, ensemble aligner, and voting strategy.
import json
import torch
from sklearn.linear_model import LogisticRegression
from ontoaligner.ontology import MaterialInformationMatOntoOMDataset, GraphTripleOMDataset
from ontoaligner.utils import metrics, xmlify
from ontoaligner.encoder import (
ConceptParentLightweightEncoder,
ConceptLLMEncoder,
ConceptParentRAGEncoder,
GraphTripleEncoder,
)
from ontoaligner.aligner import (
SimpleFuzzySMLightweight,
SBERTRetrieval,
AutoModelDecoderLLM,
ConceptLLMDataset,
MistralLLMBERTRetrieverRAG,
TransEAligner,
)
from ontoaligner.postprocess import (
TFIDFLabelMapper,
llm_postprocessor,
graph_postprocessor,
rag_heuristic_postprocessor,
)
from ontoaligner.aligner.ensemble import EnsembleLearningAligner
from ontoaligner.aligner.ensemble.voting import ReciprocalRankFusionVoting
from ontoaligner import AlignerPipeline
Load the source ontology, target ontology, and reference alignment using OntoAligner dataset classes.
source_ontology_path = "assets/MI-MatOnto/mi_ontology.xml"
target_ontology_path = "assets/MI-MatOnto/matonto_ontology.xml"
reference_matching_path = "assets/MI-MatOnto/matchings.xml"
task = MaterialInformationMatOntoOMDataset()
print("Test Task:", task)
dataset = task.collect(
source_ontology_path=source_ontology_path,
target_ontology_path=target_ontology_path,
reference_matching_path=reference_matching_path,
)
graph_dataset = GraphTripleOMDataset().collect(
source_ontology_path,
target_ontology_path,
reference_matching_path,
)
Configure the runtime settings, model paths, label mapper, RAG configuration,
and ensemble aligners. Each branch is represented by an AlignerPipeline
and may include branch-level postprocessing before voting.
device = "cuda" if torch.cuda.is_available() else "cpu"
ir_model_path = "all-MiniLM-L6-v2"
llm_model_path = "Qwen/Qwen2.5-1.5B-Instruct"
mapper = TFIDFLabelMapper(
classifier=LogisticRegression(),
ngram_range=(1, 1),
label_dict={
"yes": ["yes", "correct", "true", "same", "equivalent", "valid"],
"no": ["no", "incorrect", "false", "different", "not same", "invalid"],
},
)
retriever_config = {
"device": device,
"top_k": 5,
"threshold": 0.1,
}
llm_config = {
"device": device,
"max_length": 300,
"max_new_tokens": 10,
"batch_size": 1,
"answer_set": {
"yes": ["yes", "correct", "true", "positive", "valid"],
"no": ["no", "incorrect", "false", "negative", "invalid"],
},
}
aligners = [
(
"lightweight",
AlignerPipeline(
encoder=ConceptParentLightweightEncoder(),
aligner=SimpleFuzzySMLightweight(fuzzy_sm_threshold=0.2),
om_dataset=dataset,
),
1.0,
),
(
"sbert",
AlignerPipeline(
encoder=ConceptParentLightweightEncoder(),
aligner=SBERTRetrieval(device=device, top_k=5),
om_dataset=dataset,
load_params={"path": ir_model_path},
),
1.0,
),
(
"kge",
AlignerPipeline(
encoder=GraphTripleEncoder(),
aligner=TransEAligner(
model="TransE",
device=device,
embedding_dim=32,
num_epochs=1,
train_batch_size=32,
eval_batch_size=32,
num_negs_per_pos=1,
random_seed=42,
),
om_dataset=graph_dataset,
postprocessor=graph_postprocessor,
postprocessor_params={"threshold": 0.0},
),
1.0,
),
(
"llm",
AlignerPipeline(
encoder=ConceptLLMEncoder(),
aligner=AutoModelDecoderLLM(
device=device,
max_length=300,
max_new_tokens=20,
batch_size=1,
),
om_dataset=dataset,
llm_dataset_class=ConceptLLMDataset,
load_params={"path": llm_model_path},
postprocessor=llm_postprocessor,
postprocessor_params={
"mapper": mapper,
"interested_class": "yes",
},
),
1.0,
),
(
"rag",
AlignerPipeline(
encoder=ConceptParentRAGEncoder(),
aligner=MistralLLMBERTRetrieverRAG(
retriever_config=retriever_config,
llm_config=llm_config,
),
om_dataset=dataset,
load_params={
"llm_path": llm_model_path,
"ir_path": ir_model_path,
},
postprocessor=rag_heuristic_postprocessor,
postprocessor_params={
"topk_confidence_ratio": 3,
"topk_confidence_score": 3,
},
),
1.0,
),
]
Each branch is represented as a tuple containing the branch name, an
AlignerPipeline, and an optional branch weight.
aligners = [
("lightweight", AlignerPipeline(...), 1.0),
("sbert", AlignerPipeline(...), 1.0),
]
The branch weight controls how much influence the branch has during voting.
Initialize EnsembleLearningAligner with the configured aligners and a voting
method. The default voting method is ReciprocalRankFusionVoting.
ensemble = EnsembleLearningAligner(
aligners=aligners,
voting=ReciprocalRankFusionVoting(k=60),
)
final_matchings = ensemble.generate()
The output is a list of flat source-target correspondences sorted by score.
[
{"source": "...", "target": "...", "score": 0.9},
...
]
Compare predictions to a reference alignment and export results.
# Evaluate
evaluation = metrics.evaluation_report(
predicts=final_matchings,
references=dataset["reference"],
)
print("Ensemble Learning Evaluation Report:")
print(json.dumps(evaluation, indent=4))
Example output:
{
"intersection": 154,
"precision": 2.651058702014116,
"recall": 50.993377483443716,
"f-score": 5.040091638029782,
"predictions-len": 5809,
"reference-len": 302
}
Export the final alignment to XML (OAEI-compatible) or JSON:
xml_str = xmlify.xml_alignment_generator(matchings=final_matchings)
with open("ensemble_matchings.xml", "w", encoding="utf-8") as f:
f.write(xml_str)
with open("ensemble_matchings.json", "w", encoding="utf-8") as f:
json.dump(final_matchings, f, indent=4, ensure_ascii=False)
Note
A complete ensemble learning example is available at examples/ensemble.py.
Voting Strategies¶
Voting strategies combine normalized predictions from multiple aligners. Each branch contributes a list of predictions and a branch weight. The branch weight controls the influence of the branch during fusion.
Strategy |
Description |
Link |
|---|---|---|
|
Adds reciprocal-rank scores from each branch and ranks pairs by the fused score. |
|
|
Assigns normalized rank-based points to predictions and sums them across aligners. |
|
|
Compares target candidates pairwise for each source and scores candidates by pairwise wins. |
|
|
Computes the weighted average score for each source-target pair across aligners. |
|
|
Counts weighted branch support for each source-target pair and filters by vote settings. |
Hint
Rank-based voting is useful for heterogeneous aligners where scores are not directly comparable. Score-based voting is useful when scores come from similar model families or are already comparable.
To use voting strategies:
Import a voting method and pass it to EnsembleLearningAligner.
from ontoaligner.aligner.ensemble.voting import ReciprocalRankFusionVoting
ensemble = EnsembleLearningAligner(
aligners=aligners,
voting=ReciprocalRankFusionVoting(k=60),
)
A different voting method can be used by changing the import & voting object.
from ontoaligner.aligner.ensemble.voting import ScoreAverageVoting
ensemble = EnsembleLearningAligner(
aligners=aligners,
voting=ScoreAverageVoting(),
)
Configuration¶
Parameter |
Type |
Default |
Description |
|---|---|---|---|
aligners |
list |
— |
A list of branch tuples in the form |
voting |
BaseVoting |
|
Voting method used to combine branch predictions. |
**kwargs |
dict |
|
Additional keyword arguments forwarded to the base ontology matching model. |
Parameter |
Type |
Default |
Description |
|---|---|---|---|
k |
int |
|
Smoothing constant used in reciprocal rank fusion. |
Parameter |
Type |
Default |
Description |
|---|---|---|---|
min_votes |
int |
|
Minimum number of aligners required for a pair. |
score_threshold |
float |
|
Minimum branch score required to count a vote. |
WeightedVoting can work as majority voting when all aligners have the same
weight and min_votes is set to more than half of the total number of aligners;
score_threshold is optional.
Example use when the count of aligners is 5:
ensemble = EnsembleLearningAligner(
aligners=aligners,
voting=WeightedVoting(min_votes=3),
)
Note
For details on configuring AlignerPipeline & EnsembleLearningAligner, see:
No additional constructor parameters are required for BordaCountVoting, CondorcetVoting, ScoreAverageVoting.
Configuration Example:
ensemble = EnsembleLearningAligner(
aligners=aligners,
voting=ReciprocalRankFusionVoting(k=60),
)