FLORA: Fuzzy Logic KG Aligner¶
FLORA¶
FLORA (Fuzzy Logic Knowledge-graph Alignment) is an unsupervised system for automatic knowledge graph (KG) alignment that jointly matches entities and relations between two KGs using an iterative fuzzy-logic inference procedure. Key properties of FLORA are: 1) Unsupervised – Does not require labelled training pairs. Optional seed alignments are supported via the training-data at supervised method. 2) Holistic – Entities and relations are aligned jointly in an iterative loop. 3) Interpretable – All confidence scores are grounded in fuzzy-logic rules. 4) Provably Convergent – The iterative procedure is monotone and always terminates. 5) Dangling-Entity Aware – Entities without a counterpart in the other KG are handled gracefully. Moreover, FLORA builds on the PARIS system with three key improvements: 1) Convergence guarantees via monotone score updates. 2) Better handling of non-functional relations via per-subject functionality weighting. 3) Neural string-embedding similarity for literal matching. The following figure illustrates the overall pipeline of FLORA, from input KGs to final alignments:
ISWC 2025 Talk — FLORA Presentation by Yiwen Peng.
Note
Reference: Peng, Y., Bonald, T., Suchanek, F.M. (2026). FLORA: Unsupervised Knowledge Graph Alignment by Fuzzy Logic. In: Garijo, D., et al. The Semantic Web – ISWC 2025. ISWC 2025. Lecture Notes in Computer Science, vol 16140. Springer, Cham. https://doi.org/10.1007/978-3-032-09527-5_11
Fuzzy Logic¶
Given two KGs \(G = \langle E, R, T \rangle\) and \(G' = \langle E', R', T' \rangle\), FLORA jointly produces:
Entity alignment \(M_e = \{(e, e') \mid e \equiv e'\}\) — pairs of semantically equivalent entities.
Relation alignment \(M_r = \{(r, O, r') \mid r \mathbin{O} r',\; O \in \{\subseteq, \supseteq, \equiv\}\}\) — pairs of relations with their subsumption or equivalence type.
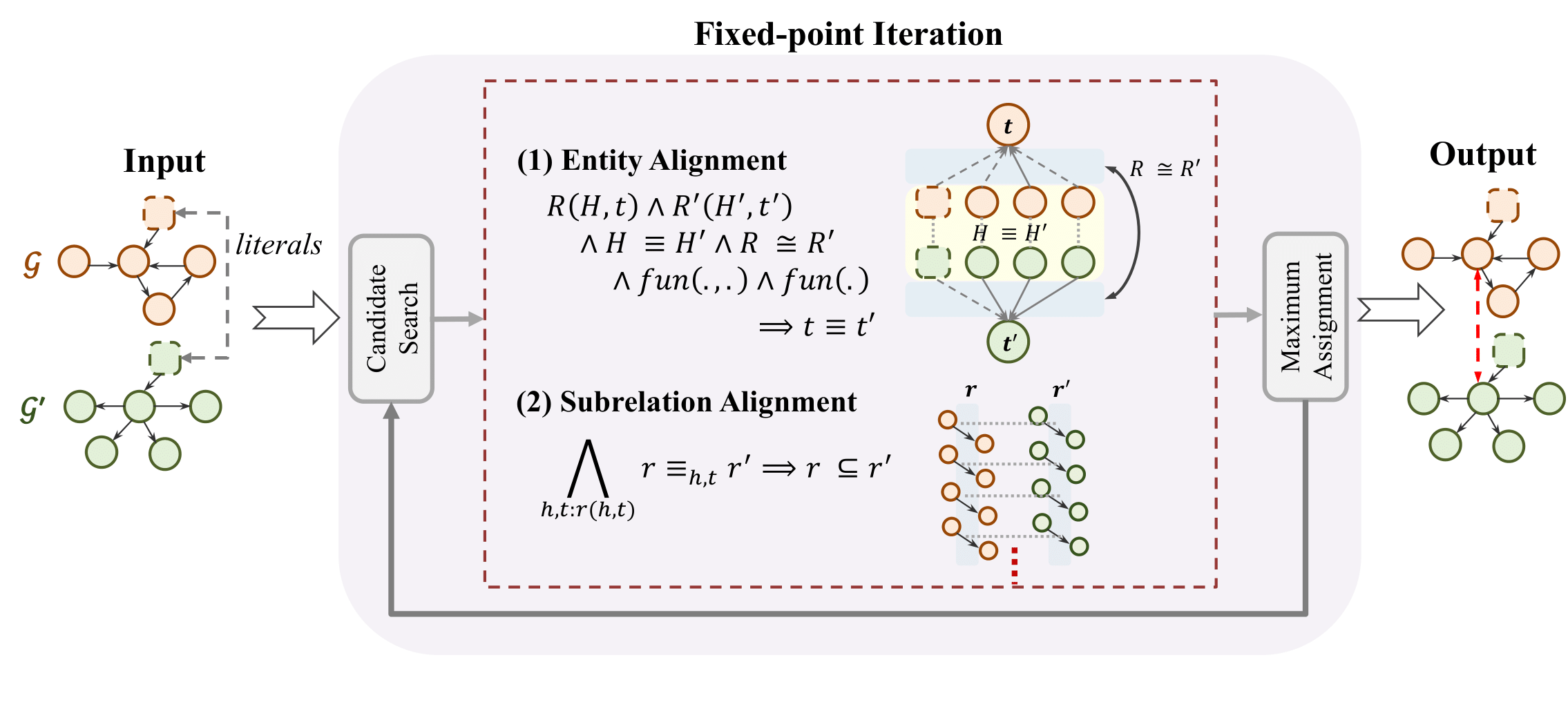
FLORA frames both tasks as a single Recursive Fuzzy Inference System: every alignment score is a value in \([0, 1]\), rules propagate scores through the graph, and an iterative fixed-point algorithm drives everything to convergence.
A relation \(r\) is functional if it tends to map each head entity to a unique tail entity. FLORA uses two flavors:
Global functionality:
A value of 1 means \(r\) is fully functional (e.g., hasCapital for most countries). High global functionality makes a relation a reliable bridge for propagating alignments.
Local functionality:
This captures exceptions: hasCapital is globally functional, but locally non-functional for South Africa (which has three capitals). Using both global and local functionality prevents spurious matches in such cases.
FLORA generalises single-relation functionality to lists of relations \(R = (r_1, \ldots, r_n)\) applied to a corresponding list of head entities \(H = (h_1, \ldots, h_n)\):
Even if no individual relation is functional, their combination can be. For example, neither BirthDateOf nor FamilyNameOf alone uniquely identifies a person, but together they usually do. This is a key improvement over PARIS, which is limited to single functional relations.
FLORA uses three aggregation functions, each chosen for a specific role:
Function |
Formula |
Used for |
|---|---|---|
min |
\(\min(p_1, \ldots, p_n)\) |
Entity rule premises — all conditions must hold; no strong premise can compensate for a weak one. |
harmonic mean |
\(\frac{n}{\sum_{i=1}^n 1/p_i}\) |
Head-list and relation-list aggregation — rewards high evidence while penalising weak conjuncts. |
α-mean |
\(\min\!\left(\alpha \cdot \frac{1}{n}\sum_i p_i,\; 1\right)\) |
Subrelation scoring — arithmetic mean scaled by benefit-of-doubt constant \(\alpha = 3\) to compensate for KG incompleteness. |
Before any iteration, FLORA computes pairwise similarity scores for all literals (strings, numbers, dates) across the two KGs. These scores are computed once and treated as fixed input variables throughout the algorithm.
Strings — cosine similarity using a small language model:
Numbers — similarity of 1 if values agree within a relative error of \(10^{-9}\), else 0.
Dates — exact match only.
If training data are provided, matched entity pairs are fixed at score 1 and also treated as input variables that are never updated. Relation similarities are initialised to a small constant \(\theta_r = 0.1\) to bootstrap the entity alignment rule on the first iteration. This value is superseded by the subrelation alignment scores in subsequent iterations.
Important
This step does not produce entity alignment scores. It produces literal similarity scores that seed the entity alignment rules in Step 2. Entity alignment scores emerge only from the iterative process.
The core of FLORA is the following rule, applied for every candidate pair of non-literal entities \(t \in E\) and \(t' \in E'\):
In plain terms: if head entities \(H\) and \(H'\) are already aligned, if the relation lists \(R\) and \(R'\) are similar and jointly functional (both globally and locally), and if both relation lists actually connect those heads to \(t\) and \(t'\) respectively, then \(t\) and \(t'\) receive an alignment score equal to the minimum of all these premise values. The sub-expressions in the rule are themselves output variables of subordinate rules:
Head-list alignment \(H \equiv H'\), were \(h_1 \equiv h'_1 \;\wedge\; \cdots \;\wedge\; h_n \equiv h'_n \;\xrightarrow{\text{hmean}}\; H \equiv H'\), in which each individual head alignment \(h_i \equiv h'_i\) is either itself an output variable (from a previous application of the entity rule) or a literal similarity score (from Step 1).
Relation-list similarity \(R \cong R'\), were \(r_1 \cong r'_1 \;\wedge\; \cdots \;\wedge\; r_n \cong r'_n \;\xrightarrow{\text{hmean}}\; R \cong R'\), where \(r \cong r'\) holds (with firing strength 1) if \(r \subseteq r'\) or \(r' \subseteq r\) — i.e., one is a subrelation of the other. If multiple rules imply the same output variable \(t \equiv t'\), its score is the maximum of all firing strengths, in line with the FIS solver (Algorithm 1).
For each pair of relations \(r \in R\) and \(r' \in R'\), FLORA measures how consistently the facts of \(r\) are also facts of \(r'\) under the current entity alignment. Furthermore, For each fact \(r(h, t)\) in \(G\), it looks for a counterpart \(r'(h', t')\) in \(G'\) where \(h \equiv h'\) and \(t \equiv t'\) already hold. Each such coincidence produces a local score:
The subrelation score is then:
The \(\alpha\text{-mean}\) aggregation (arithmetic mean multiplied by \(\alpha = 3\), capped at 1) accounts for KG incompleteness under the Open World Assumption: some facts \(r'(h', t')\) may simply be absent from \(G'\), so a raw average would underestimate the true subrelation score.
Note
Relation alignment is asymmetric by design. FLORA computes \(r \subseteq r'\) and \(r' \subseteq r\) independently. Equivalence \(r \equiv r'\) is only declared when both subsumptions hold. This naturally handles cases such as parent (DBpedia) being a superrelation of father (Wikidata), as illustrated in Figure 1 of the paper.
Steps 2 and 3 are applied alternately. After each full pass, every output variable takes the maximum over all rules that imply it. The process terminates (early stopping) when the total matching score increases by less than \(\varepsilon = 0.01\).
Convergence guarantee. Because all aggregation functions (min, harmonic mean, α-mean, max) are continuous and non-decreasing, the Knaster–Tarski fixed-point theorem guarantees that Algorithm 1 converges to the unique least fixed point of the Recursive FIS. This is Theorem 1 of the paper and is a key theoretical advantage over PARIS, which has no such guarantee. After convergence:
Entity pairs with scores below \(\theta_e = 0.1\) are discarded.
A maximum assignment is enforced for entities: each entity \(e \in E\) retains only its single highest-scored counterpart in \(E'\) (one-to-one constraint). Relations are not subject to this constraint — all subrelation pairs with scores above zero are kept.
Usage¶
Import the FLORA aligner, its dataset/encoder helpers, and utility modules.
import json
from ontoaligner.ontology import FLORAOMDataset
from ontoaligner.encoder import FLORAEncoder
from ontoaligner.aligner.flora import FLORAAligner
from ontoaligner.utils import metrics, xmlify
from ontoaligner.aligner.flora.postprocessor import (
flora_threshold_postprocessor,
flora_bilateral_postprocessor,
flora_1to1_postprocessor,
)
Note
The FLORAAligner class accepts configuration parameters to customize
behaviour. See Configuration below.
FLORAOMDataset.collect() calls FLORAOntology.parse() for each KG,
which loads the Turtle or XML file into a FLORA Graph and extracts all
alignment-relevant data.
# Initialize dataset, optionally naming the use-case
task = FLORAOMDataset(ontology_name="memoryalpha-stexpanded")
dataset = task.collect(
source_ontology_path="memoryalpha-stexpanded/source.xml",
target_ontology_path="memoryalpha-stexpanded/target.xml",
reference_matching_path="memoryalpha-stexpanded/reference.xml", # optional: for evaluation
)
Each side of dataset is a single-element list containing:
dataset["source"][0] == {
"entities": [{"iri": "http://...", "label": "MyEntity"}, ...],
"predicates": {...},
"triples": [("http://subj", "pred", "http://obj"), ...],
"graph": <Graph> # ← passed to the aligner
}
.. warning::
The input should be either XML (which the existing module will convert it into N-Turtle) or Turtle with `N-Triples format <https://en.wikipedia.org/wiki/N-Triples>`_. The aligner relies on the structured output of the parser, so other formats may require custom parsing.
FLORAEncoder extracts the two pre-loaded Graph objects from the
structured parser output and returns [kg1_graph, kg2_graph].
encoder_model = FLORAEncoder()
encoder_output = encoder_model(source=dataset["source"],
target=dataset["target"])
# encoder_output == [kg1_graph, kg2_graph]
# Both are fully loaded FLORA Graph objects, ready for the aligner.
Create a FLORA aligner instance and configure parameters as needed.
aligner = FLORAAligner(
# Subrelation inference
alpha=3.0, # Benefit-of-doubt parameter
relinit=0.1, # Initial score for non-identical predicates
# Literal bootstrapping
init_threshold=0.2, # Min semantic similarity threshold
string_identity=True, # Use exact string matching (no embeddings)
# Entity matching
gramN=100, # Max evidential facts per entity
# Convergence
epsilon=0.01, # Stop when score change < epsilon
max_iterations=100, # Safety cap on iterations
# Functionality computation
ngrams=[1, 2], # N-gram sizes for predicate functionality
# Optional: seed alignments
training_data=None, # Tab-separated seed alignments file
# Embeddings
# model_id='Lihuchen/pearl_small', # Hugging Face model for literal similarity,
# set this if `string_identity` is False
device='cuda', # Uncomment to force GPU (auto-detects by default)
verbose=True, # Enable debug logging to see FLORA progress
workers=30, # Number of workers for multiprocessing
)
See Configuration below for a complete parameter reference.
Pass the encoder output to generate() — identical to every other aligner.
matchings = aligner.generate(input_data=encoder_output)
The output is a list of entity alignment predictions:
[
{
"source": "http://example.org/entity/E1",
"target": "http://example.org/entity/E2",
"score": 0.91
},
...
]
Refine and filter the raw alignments using post-processing functions.
# Apply thresholding to filter weak matches
instance_alignments, class_alignments, predicate_alignments = flora_threshold_postprocessor(matchings,
prefix1="http://dbkwik.webdatacommons.org/memory-alpha.wikia.com",
prefix2='http://dbkwik.webdatacommons.org/stexpanded.wikia.com',
threshold=0.1)
# Bilateral match refinement
bilateral_alignments = flora_bilateral_postprocessor(same_as_scores = aligner.get_same_as_scores(),
source_prefix="http://dbkwik.webdatacommons.org/memory-alpha.wikia.com")
# 1-to-1 matching enforcement
one2one_alignments = flora_1to1_postprocessor(same_as_scores = aligner.get_same_as_scores())
The output is a refined list of alignments, ready for evaluation or export.
Compare predictions to a reference alignment.
evaluation = metrics.evaluation_report(predicts=bilateral_alignments, references=dataset["reference"])
print("\n Bilateral Alignments Evaluation Results:")
print(f" Precision: {evaluation.get('precision', 'N/A'):.3f}")
print(f" Recall: {evaluation.get('recall', 'N/A'):.3f}")
print(f" F1-Score: {evaluation.get('f-score', 'N/A'):.3f}")
evaluation = metrics.evaluation_report(predicts=one2one_alignments, references=dataset["reference"])
print("\n 1-to-1 Alignments Evaluation Results:")
print(f" Precision: {evaluation.get('precision', 'N/A'):.3f}")
print(f" Recall: {evaluation.get('recall', 'N/A'):.3f}")
print(f" F1-Score: {evaluation.get('f-score', 'N/A'):.3f}")
evaluation = metrics.evaluation_report(
predicts=instance_alignments,
references=[item for item in dataset['reference'] if item['type'] == 'instance']
)
print("\n Instance alignments Results:")
print(f" Precision: {evaluation.get('precision', 'N/A'):.3f}")
print(f" Recall: {evaluation.get('recall', 'N/A'):.3f}")
print(f" F1-Score: {evaluation.get('f-score', 'N/A'):.3f}")
evaluation = metrics.evaluation_report(
predicts=class_alignments,
references=[item for item in dataset['reference'] if item['type'] == 'class']
)
print("\n Class Alignments Results:")
print(f" Precision: {evaluation.get('precision', 'N/A'):.3f}")
print(f" Recall: {evaluation.get('recall', 'N/A'):.3f}")
print(f" F1-Score: {evaluation.get('f-score', 'N/A'):.3f}")
evaluation = metrics.evaluation_report(
predicts=predicate_alignments,
references=[item for item in dataset['reference'] if item['type'] == 'predicate']
)
print("\n Predicate Alignments Results:")
print(f" Precision: {evaluation.get('precision', 'N/A'):.3f}")
print(f" Recall: {evaluation.get('recall', 'N/A'):.3f}")
print(f" F1-Score: {evaluation.get('f-score', 'N/A'):.3f}")
Example output:
{
"intersection": 120,
"precision": 85.7,
"recall": 78.4,
"f-score": 81.9,
"predictions-len": 140,
"reference-len": 153
}
Next, save the alignment results in XML or JSON format.
xml_str = xmlify.xml_alignment_generator(matchings=bilateral_alignments)
with open("bilateral_alignments.xml", "w", encoding="utf-8") as f:
f.write(xml_str)
with open("bilateral_alignments.json", "w", encoding="utf-8") as f:
json.dump(bilateral_alignments, f, indent=4, ensure_ascii=False)
Configuration¶
The FLORAAligner class accepts the following parameters to customize alignment behaviour.
Parameter |
Type |
Default |
Description |
|---|---|---|---|
alpha |
float |
3.0 |
Benefit-of-doubt parameter for predicate subsumption scoring. Higher values (e.g., 5.0) are more lenient; lower values (e.g., 1.0) are stricter. |
relinit |
float |
0.1 |
Initial score for predicates that do not match identically. Used when bootstrapping predicate subsumption. |
Parameter
Type
Default
Description
init_threshold
float
0.7
Minimum semantic similarity score for matching string literals during bootstrapping. Range: [0.0, 1.0]. Higher values require more similar literals.
string_identity
bool
False
If
True, use exact string matching instead of neural embeddings for literals. This is faster but may yield lower recall.model_id
str
'Lihuchen/pearl_small'Hugging Face model ID for semantic embedding of string literals. Set to
Noneto disable embeddings.
- emb_path
str
'path/to/pre-encoded-embeddings'Optional path to pretrained (encoded) embeddings using Hugging Face model for string literals. Set to
Noneto this if you are whiling to use Hugging Face model.
Parameter |
Type |
Default |
Description |
|---|---|---|---|
gramN |
int |
100 |
Maximum number of evidential triples (facts) to consider per entity during matching. Increase for more evidence; decrease for speed. |
Parameter |
Type |
Default |
Description |
|---|---|---|---|
epsilon |
float |
0.01 |
Convergence threshold. Iteration stops when the change in total alignment score
is less than |
max_iterations |
int |
100 |
Maximum number of main-loop iterations. Acts as a safety cap. |
Parameter |
Type |
Default |
Description |
|---|---|---|---|
ngrams |
List[int] |
|
N-gram sizes for predicate functionality computation.
E.g., |
Parameter |
Type |
Default |
Description |
|---|---|---|---|
training_data |
str or None |
None |
Path to a tab-separated seed alignment file. Optional third column provides seed confidence (defaults to 1.0). See format below. |
<http://kg1.org/E1> <http://kg2.org/E1>
<http://kg1.org/E2> <http://kg2.org/E2> 0.95
Parameter |
Type |
Default |
Description |
|---|---|---|---|
verbose |
bool |
False |
Enable debug logging for detailed aligner output. |
workers |
int or None |
4 |
Number of parallel workers for multiprocessing (set to None to auto-detect CPU count). |
Parameter |
Type |
Default |
Description |
|---|---|---|---|
device |
str or None |
None |
Device for embeddings: |
batch_size |
int or None |
32 |
Batch size for embedding computations. |
Complete Example
# Strict, supervised mode
aligner = FLORAAligner(
alpha=1.0, # Conservative subrelation scoring
init_threshold=0.9, # High literal similarity required
epsilon=0.001, # Strict convergence
training_data="seeds.tsv", # Use known pairs
string_identity=False # Still use embeddings for unknown literals
)
# Fast, lightweight mode
aligner = FLORAAligner(
string_identity=True, # No embeddings
gramN=50, # Fewer evidence facts
max_iterations=20 # Fewer iterations
)
Advanced Usage¶
If seed/training entity pairs are available, you can bootstrap the alignment:
aligner = FLORAAligner(training_data="seed_links.tsv")
matchings = aligner.generate(input_data=encoder_output)
The seed file should contain one alignment pair per line, tab-separated:
<http://kg1.org/E1> <http://kg2.org/E1>
<http://kg1.org/E2> <http://kg2.org/E2> 0.95
An optional third column provides the seed confidence score (defaults to 1.0 if omitted).
For a lightweight run without downloading/running the embedding model, set string_identity=True:
aligner = FLORAAligner(string_identity=True)
matchings = aligner.generate(input_data=encoder_output)
This mode is faster and uses less memory but may yield lower recall on datasets where equivalent literals differ in whitespace, casing, or phrasing.
For large KGs or repeated experiments you can pre-compute and cache the literal string embeddings:
from ontoaligner.aligner.flora import FLORALiteralsEmbedding
from ontoaligner.ontology import FLORAOntology
# Load KGs
kb1 = FLORAOntology().load_ontology(input_file_path='path/to/kg.ttl') # load KG1
kb2 = FLORAOntology().load_ontology(input_file_path='path/to/kg.ttl') # load KG2
# Compute and save embeddings
embedding_model = FLORALiteralsEmbedding(model_id='Lihuchen/pearl_small', identity=False)
embedding_model.encode_save(kb1, kb2, emb_path="my_embeddings/")
Then reuse in multiple experiments:
# These embeddings will be loaded from disk instead of recomputed
aligner = FLORAAligner(emb_path='my_embeddings/')
# (The aligner will look for embeddings in default locations)
If you prefer to work directly with FLORA’s native Graph
data structure instead of using the standard dataset pipelines, you can load TTL/XML files directly:
from ontoaligner.ontology.flora import Graph
# Load Turtle files directly into Graph objects
kg1=Graph().load_turtle_file("path/to/kg1.ttl")
kg2=Graph().load_turtle_file("path/to/kg2.ttl")
# kg1 and kg2 are now Graph objects ready for the aligner
aligner = FLORAAligner()
matchings = aligner.generate(input_data=[kg1, kg2])
Graph Class Overview
The Graph is an in-memory directed multigraph optimized for KG alignment:
from ontoaligner.ontology.flora import Graph
# Create an empty graph
graph = Graph()
# Add triples manually
graph.add(("http://example.org/John", "http://example.org/knows", "http://example.org/Jane"))
graph.add(("http://example.org/John", "http://example.org/age", '"25"^^http://www.w3.org/2001/XMLSchema#integer'))
# Check if a triple exists
if ("http://example.org/John", "http://example.org/knows", "http://example.org/Jane") in graph:
print("Triple found!")
# Iterate over all triples
for subject, predicate, obj in graph:
print(f"{subject} -> {predicate} -> {obj}")
# Get predicate statistics
predicates = graph.predicates() # Returns {predicate: count, ...}
print(f"Total predicates: {len(predicates)}")
# Load from a TTL file
graph.load_turtle_file("path/to/ontology.ttl")
Key Features of Graph:
Bidirectional indexing: Forward (subject→predicate→objects) and reverse (predicate→subject→objects) indices for fast lookups.
Automatic inverse arcs: For every triple
(s, p, o), the inverse(o, p+"-", s)is automatically added.Efficient storage: Uses nested dictionaries with sets for O(1) membership testing.
Lazy predicate counting: Predicates are cached and recomputed only when modified.
The FLORARDFWriter class writes alignment results back to RDF/Turtle format:
from ontoaligner.aligner.flora import FLORARDFWriter, FLORAAligner
# Run alignment
aligner = FLORAAligner()
matchings = aligner.generate(input_data=[kg1, kg2])
# Extract entity and predicate alignments from the aligner
same_as_scores = aligner.get_same_as_scores()
predicate_scores = aligner.get_predicate2super_predicate()
# Create an RDF writer with namespace prefixes
prefixes = {
'ex': 'http://example.org/',
'owl': 'http://www.w3.org/2002/07/owl#',
'rdfs': 'http://www.w3.org/2000/01/rdf-schema#',
'align': 'http://knowledgeweb.semanticweb.org/heterogeneity/alignment#'
}
writer = FLORARDFWriter(prefixes=prefixes)
# Write alignments to file
writer.write(
output_path="alignments.ttl",
kb1=kg1,
kb2=kg2,
predicate2super_predicate=predicate_scores,
same_as_scores=same_as_scores
)
Output Format
The generated Turtle file contains:
Namespace declarations — Standard RDF prefixes at the top:
@prefix ex: <http://example.org/> . @prefix owl: <http://www.w3.org/2002/07/owl#> . @prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
Predicate subsumption relationships — Using
rdfs:subPropertyOf:ex:father rdfs:subPropertyOf ex:parent . # 0.92
Entity equivalence mappings — Using
owl:sameAs:ex:John owl:sameAs ex:John_DBpedia . # 0.95 ex:Jane owl:sameAs ex:jane_dbpedia . # 0.88
The # score suffix (as a comment) indicates the confidence of each alignment.
Pre-defined Prefixes from ontoaligner.aligner.flora.fuzzy_logic.prefixes
The module prefixes.py provides two built-in prefix dictionaries with well-known RDF/OWL vocabularies:
Import and use the prefixes dictionary for general-purpose RDF/OWL vocabularies:
from ontoaligner.aligner.flora import prefixes
writer = FLORARDFWriter(prefixes=prefixes)
Supported namespaces:
Prefix |
Namespace URI |
|---|---|
|
|
|
|
|
|
|
|
|
Wikidata statement value properties |
|
Wikidata qualifier value properties |
|
Wikidata reference value properties |
|
RDF/RDFS/OWL core vocabularies |
|
XML Schema datatypes |
|
Simple Knowledge Organization System |
|
schema.org vocabulary |
|
Friend of a Friend |
|
Dublin Core Terms |
|
Creative Commons |
|
OGC GeoSPARQL |
|
W3C PROV ontology |
|
SHACL (Shapes Constraint Language) |
|
Wikibase ontology |
|
OntoLex vocabulary |
|
YAGO Schema |
For DBpedia-centric alignments, use prefixes_dbp which includes multilingual support:
from ontoaligner.aligner.flora import prefixes_dbp
writer = FLORARDFWriter(prefixes=prefixes_dbp)
Supported DBpedia resources and properties:
Prefix |
Description |
|---|---|
|
DBpedia English resource namespace |
|
DBpedia resources in French, Chinese, Japanese |
|
DBpedia ontology (classes and properties) |
|
DBpedia properties in multiple languages |
|
DBpedia datatypes |
|
Standard RDF vocabularies (overlaps with |
|
Dublin Core (elements and terms) |
|
SKOS vocabulary |
|
OGC WGS84 Geo Positioning |
Important
What is supported:
✅ Custom prefix dictionaries – Pass any
Dict[str, str]mapping prefix names to URIs.✅ Pre-configured vocabularies – Use
prefixesorprefixes_dbpfrom the module.✅ Mixed vocabularies – Combine multiple prefix sources into a single dict.
✅ Multilingual DBpedia –
prefixes_dbphandles English, French, Chinese, Japanese.✅ Standard RDF/OWL predicates –
owl:sameAsandrdfs:subPropertyOfare always supported.
What is NOT supported:
❌ Automatic namespace detection – Prefixes must be explicitly provided; the writer does not introspect your KGs.
❌ Custom alignment predicates – The writer always uses
owl:sameAsfor entities andrdfs:subPropertyOffor predicates. Other predicates (e.g.,skos:closeMatch) are not generated.❌ Filtering by namespace – All IRIs are written as-is; use post-processing to filter by namespace if needed.
❌ Blank node abbreviation – IRIs are always written in full form, not abbreviated with prefixes in the triples themselves.
❌ Alignment metadata – Scores are appended as tab-separated comments only; no formal alignment vocabulary (e.g., from ALIGNAPI) is used.
Why Use FLORARDFWriter?
Standard RDF format: Output is directly readable by any RDF tool or SPARQL engine.
Interpretable scores: Comments preserve confidence scores for downstream analysis.
Integration-ready: Results can be loaded into ontology editors (Protégé, TopBraid) or linked data platforms.
Reproducible: Combined with seed alignments, enables iterative refinement workflows.
Hint
See also the Package Reference > FLORA Aligner.