Retrieval-Augmented Generation¶
LLMs4OM¶
The LLMs4OM: Matching Ontologies with Large Language Models work introduces a RAG approach for OA. The retrieval augmented generation (RAG) module at OntoAligner is driven by a LLMs4OM framework, a novel approach for effective ontology alignment using LLMs. This framework utilizes two modules for retrieval and matching, respectively, enhanced by zero-shot prompting across three ontology representations: concept, concept-parent, and concept-children. The LLMs4OM framework, can match and even surpass the performance of traditional OM systems, particularly in complex matching scenarios. The LLMs4OM framework is presented in the following diagram.
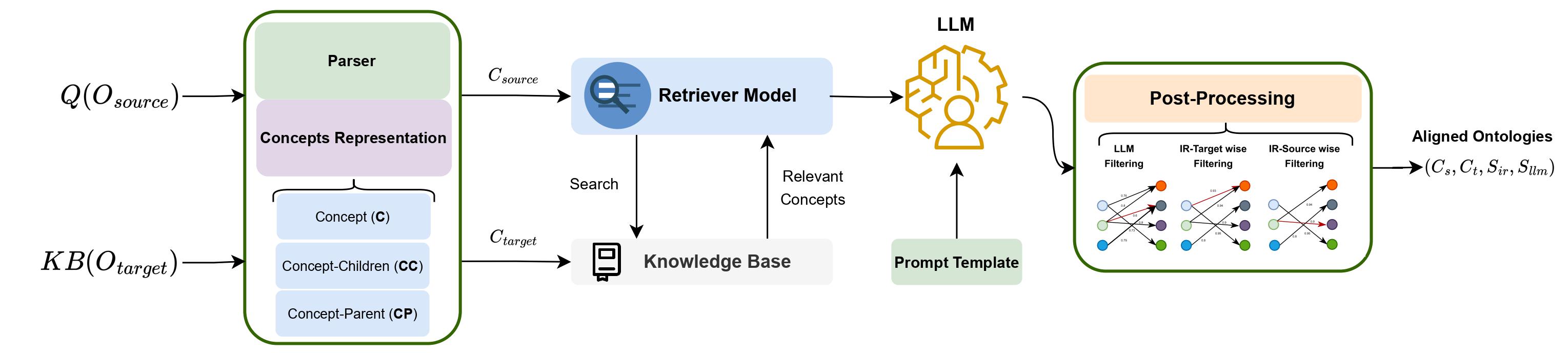
This offers a RAG approach within LLMs for OM. LLMs4OM uses \(O_{source}\) as query \(Q(O_{source})\) to retrieve possible matches for for any \(C_s \in C_{source}\) from \(C_{target} \in O_{target}\). Where, \(C_{target}\) is stored in the knowledge base \(KB(O_{target})\). Later, \(C_{s}\) and obtained \(C_t \in C_{target}\) are used to query the LLM to check whether the \((C_s, C_t)\) pair is a match. As shown in above diagram, the framework comprises four main steps: 1) Concept representation, 2) Retriever model, 3) LLM, and 4) Post-processing. But within the OntoAligner we we adapted the workflow into a parser, encoder, alignment, post-processing, evaluate, and export steps.
ESWC 2024 Talk — LLMs4OM Presentation by Hamed Babaei Giglou.
Note
Reference: Babaei Giglou, H., D’Souza, J., Engel, F., Auer, S. (2025). LLMs4OM: Matching Ontologies with Large Language Models. In: Meroño Peñuela, A., et al. The Semantic Web: ESWC 2024 Satellite Events. ESWC 2024. Lecture Notes in Computer Science, vol 15344. Springer, Cham. https://doi.org/10.1007/978-3-031-78952-6_3
Usage¶
This guide walks you through the process of ontology matching using the OntoAligner library, leveraging RAG techniques. Starting with the necessary module imports, it defines a task and loads source and target ontologies along with reference matchings. The tutorial then encodes the ontologies using a specialized encoder, configures a retriever and an LLM, and generates predictions. Finally, it demonstrates two postprocessing techniques—heuristic and hybrid—followed by saving the matched alignments in XML format, ready for use or further analysis.
# Step1. Lets import Required Modules
import json
from ontoaligner.ontology import MaterialInformationMatOntoOMDataset
from ontoaligner.utils import metrics, xmlify
from ontoaligner.aligner import MistralLLMBERTRetrieverRAG
from ontoaligner.encoder import ConceptParentRAGEncoder
from ontoaligner.postprocess import rag_hybrid_postprocessor, rag_heuristic_postprocessor
#Step 2. Define the Task and Load Ontologies
task = MaterialInformationMatOntoOMDataset()
print("Test Task:", task)
dataset = task.collect(
source_ontology_path="../assets/MI-MatOnto/mi_ontology.xml",
target_ontology_path="../assets/MI-MatOnto/matonto_ontology.xml",
reference_matching_path="../assets/MI-MatOnto/matchings.xml"
)
# Step 3. Encode Ontologies
encoder_model = ConceptParentRAGEncoder()
encoded_ontology = encoder_model(source=dataset['source'], target=dataset['target'])
#Step 4. Configure the Retriever and LLM
retriever_config = {"device": 'cuda', "top_k": 5, "threshold": 0.1}
llm_config = {
"device": "cuda", "batch_size": 32,
"answer_set": {"yes": ["yes", "true"], "no": ["no", "false"]}
}
}
# Step 5. Generate Predictions
model = MistralLLMBERTRetrieverRAG(retriever_config=retriever_config, llm_config=llm_config)
model.load(llm_path = "mistralai/Mistral-7B-v0.3", ir_path="all-MiniLM-L6-v2")
predicts = model.generate(input_data=encoded_ontology)
# Step 6. Postprocess Matches
# Heuristic Postprocessing
heuristic_matchings, heuristic_configs = rag_heuristic_postprocessor(predicts=predicts, topk_confidence_ratio=3, topk_confidence_score=3)
evaluation = metrics.evaluation_report(predicts=heuristic_matchings, references=dataset['reference'])
print("Heuristic Matching Evaluation Report:", json.dumps(evaluation, indent=4))
print("Heuristic Matching Obtained Configuration:", heuristic_configs)
# Hybrid Postprocessing
hybrid_matchings, hybrid_configs = rag_hybrid_postprocessor(predicts=predicts, ir_score_threshold=0.1, llm_confidence_th=0.8)
evaluation = metrics.evaluation_report(predicts=hybrid_matchings, references=dataset['reference'])
print("Hybrid Matching Evaluation Report:", json.dumps(evaluation, indent=4))
print("Hybrid Matching Obtained Configuration:", hybrid_configs)
# Step 7. Save Matchings in XML Format
xml_str = xmlify.xml_alignment_generator(matchings=hybrid_matchings)
output_file_path = "matchings.xml"
with open(output_file_path, "w", encoding="utf-8") as xml_file:
xml_file.write(xml_str)
In this tutorial, we demonstrated:
Loading and encoding ontologies
Using Mistral LLM with RAG for ontology matching
Refining results with heuristic and hybrid postprocessing
Saving results in XML format
Hint
You can customize the configurations and thresholds based on your specific dataset and use case. For more details, refer to the Postprocess
Embedded RAG aligners within OntoAligner:
RAG Aligner |
Description |
Link |
|---|---|---|
|
Uses Falcon LLM with Ada-based dense retrieval. |
|
|
Uses Falcon LLM with BERT-based retrieval for contextual matching. |
|
|
Uses OpenAI GPT (e.g., GPT-4) with Ada-based retriever. |
|
|
Combines OpenAI GPT models with BERT-based retrieval. |
|
|
Wraps LLaMA models with Ada retriever for hybrid RAG-based alignment. |
|
|
Uses LLaMA models with BERT for semantic retrieval. |
|
|
Utilizes MPT models with Ada retriever for alignment generation. |
|
|
MPT model with BERT-based retrieval for enhanced context grounding. |
|
|
Uses Mamba LLM with Ada retriever for token-efficient alignment. |
|
|
Mamba LLM paired with BERT retriever for structured knowledge alignment. |
|
|
Mistral model with Ada retriever for compact and fast RAG workflows. |
|
|
Mistral model enhanced with BERT-based retrieval. |
|
|
Vicuna model using Ada retrieval for alignment generation. |
|
|
Vicuna model with BERT retriever for high-accuracy RAG-based alignment. |
FewShot-RAG Aligner¶
FewShot-RAG aligner is an extension of the RAG aligner, designed for few-shot learning based alignment. The FewShot RAG workflow is the same as RAG but with two differences:
You only need to use
FewShotEncoderencoders as follows, and since a few-shot model uses multiple examples you might also provide only specific examples from reference or other examples as a fewshot samples.
from ontoaligner.encoder import ConceptParentFewShotEncoder
encoder_model = ConceptParentFewShotEncoder()
encoded_ontology = encoder_model(source=dataset['source'],
target=dataset['target'],
reference=dataset['reference'])
Next, use a Fewshot Retrieval-Augmented Generation (RAG) model for ontology alignment.
from ontoaligner.aligner import MistralLLMBERTRetrieverFSRAG
model = MistralLLMBERTRetrieverFSRAG(positive_ratio=0.7, n_shots=5, **config)
Embedded FewShot-RAG aligners within OntoAligner:
FewShot-RAG Aligner |
Description |
Link |
|---|---|---|
|
Falcon LLM with Ada retriever and few-shot examples for enhanced alignment. |
|
|
Falcon LLM with BERT-based retrieval in a few-shot setup. |
|
|
OpenAI GPT with Ada retriever for few-shot RAG alignment. |
|
|
Combines OpenAI GPT and BERT retriever with few-shot prompting. |
|
|
LLaMA model with Ada retriever for prompt-efficient few-shot alignment. |
|
|
LLaMA with BERT retriever in a few-shot reasoning framework. |
|
|
MPT LLM with Ada-based retrieval in few-shot alignment generation. |
|
|
MPT model using BERT retriever and few-shot prompting for improved accuracy. |
|
|
Mamba LLM integrated with Ada retriever for low-latency few-shot alignment. |
|
|
Mamba model paired with BERT-based retrieval and few-shot capabilities. |
|
|
Mistral LLM with Ada retriever and few-shot support. |
|
|
Mistral model with BERT retrieval, enhanced by few-shot prompting. |
|
|
Vicuna model with Ada retriever for fast, few-shot alignment. |
|
|
Vicuna with BERT retriever in a few-shot setting for high-precision alignment. |
ICV-RAG Aligner¶
This RAG variant performs ontology matching using ConceptRAGEncoder only. The In-Contect Vectors introduced by [1](https://github.com/shengliu66/ICV) tackle in-context learning as in-context vectors (ICV). We used LLMs in this perspective in the RAG module. The workflow is the same as RAG or FewShot RAG with the following differences:
Incorporate the
ConceptRAGEncoderand also provide reference (or examples to build up the ICV vectors).
from ontoaligner.encoder import ConceptRAGEncoder
encoder_model = ConceptRAGEncoder()
encoded_ontology = encoder_model(source=dataset['source'], target=dataset['target'], reference=dataset['reference'])
Next, import an ICV-RAG model. Here, we use the Falcon model:
from ontoaligner.aligner import FalconLLMBERTRetrieverICVRAG
model = FalconLLMBERTRetrieverICVRAG(**config)
model.load(llm_path="tiiuae/falcon-7b", ir_path="all-MiniLM-L6-v2")
Embedded ICV-RAG aligners within OntoAligner:
ICV-RAG Aligner |
Description |
Link |
|---|---|---|
|
Falcon LLM with Ada retriever for iterative consistency verification (ICV) alignment. |
|
|
Falcon LLM combined with BERT-based retriever for ICV-guided alignment. |
|
|
LLaMA model with Ada retriever optimized for ICV-based reasoning. |
|
|
LLaMA model paired with BERT retriever for ICV-driven alignment. |
|
|
MPT model with Ada retrieval for consistency-verified RAG alignment. |
|
|
MPT LLM with BERT retriever in an ICV pipeline for robust alignment. |
|
|
Vicuna LLM with Ada retriever for ICV-RAG tasks. |
|
|
Vicuna model paired with BERT-based retrieval for iterative consistency verification. |
Customized-RAG Aligner¶
You can use custom LLMs with RAG for alignment. Below, we define two classes, each combining a retrieval mechanism with a LLMs to implement RAG aligner functionality.
from ontoaligner.aligner import (
TFIDFRetrieval,
SBERTRetrieval,
AutoModelDecoderRAGLLM,
AutoModelDecoderRAGLLMV2,
RAG
)
class QwenLLMTFIDFRetrieverRAG(RAG):
Retrieval = TFIDFRetrieval
LLM = AutoModelDecoderRAGLLMV2
class MinistralLLMBERTRetrieverRAG(RAG):
Retrieval = SBERTRetrieval
LLM = AutoModelDecoderRAGLLM
As you can see, QwenLLMTFIDFRetrieverRAG Utilizes TFIDFRetrieval for lightweight retriever with Qwen LLM. While, MinistralLLMBERTRetrieverRAG Employs SBERTRetrieval for retriever using sentence transformers and Ministral LLM.
AutoModelDecoderRAGLLMV2 and AutoModelDecoderRAGLLM Differences:
The primary distinction between AutoModelDecoderRAGLLMV2 and AutoModelDecoderRAGLLM lies in the enhanced functionality of the former. AutoModelDecoderRAGLLMV2 includes additional methods (as presented in the following) for better classification and token validation. Overall, these classes enable seamless integration of retrieval mechanisms with LLM-based generation, making them powerful tools for ontology alignment and other domain-specific applications.
def get_probas_yes_no(self, outputs):
"""Retrieves the probabilities for the "yes" and "no" labels from model output."""
probas_yes_no = (outputs.scores[0][:, self.answer_sets_token_id["yes"] +
self.answer_sets_token_id["no"]].float().softmax(-1))
return probas_yes_no
def check_answer_set_tokenizer(self, answer: str) -> bool:
"""Checks if the tokenizer produces a single token for a given answer string."""
return len(self.tokenizer(answer).input_ids) == 1
In another approach you can simply use the RAG class and provide the retriever and LLM as follows in a light configuration manner:
from ontoaligner.aligner import RAG, TFIDFRetrieval, AutoModelDecoderRAGLLMV2
custom_rag = RAG(retrieval = TFIDFRetrieval,
llm = AutoModelDecoderRAGLLMV2,
retriever_config = ...,
llm_config = ...)